下面是使用neo4j构建知识图谱的简明教程,通过一番折腾发现,学习使用一个工具最快的方法不是看文档,而是看视频,然后实操,并记录。
neo4j功能简介
neo4j是一个图形数据关联软件。
可以使用它来构建和维护知识图谱。
知识图谱是智能教育的基础,它是学习者画像、智能推荐、学习分析、智慧内容以及智能导师的前提。
本案例尝试使用三元组构建图谱,所谓三元组是:节点1-连接-节点2。
首先导入csv需要将文件放置在import文件夹中,从neo4j面板可以打开这个文件夹。
每次修改这个文件夹,可能需要重启neo4j,否则可能无法加载。另外确保文件名一致。
常用命令
清空已有节点和关系
MATCH (n) DETACH DELETE n
导入CSV文件
LOAD CSV WITH HEADERS FROM "file:///node1.csv" AS line
MERGE (z:概念1{name:line.node1})
LOAD CSV WITH HEADERS FROM "file:///node2.csv" AS line
MERGE (z:概念2{name:line.node2})
LOAD CSV WITH HEADERS FROM "file:///tup.csv" AS line
match (from:概念1{name:line.node1}),(to:概念2{name:line.node2})
merge (from)-[r:关联{name:line.link}]->(to)导入并创建节点和关系
LOAD CSV FROM 'file:///tup.csv' AS line CREATE (:Map { linkID: line[0], nod1: line[1], link: line[2], nod2:line[3] });
LOAD CSV FROM 'file:///tup.csv' AS line
CREATE (line[1])-[r:line[2]]->(line[3]);显示所有关系
MATCH (n) RETURN (n)
MATCH (n:概念1{name:"细胞"}) RETURN n
MATCH (n:概念1{name:"细胞"})-[]-() RETURN n利用apoc创建三元图
apoc是一个插件,需要先安装,然后才能调用。
创建概念1节点
LOAD CSV WITH HEADERS FROM "file:///node1.csv" AS line
call apoc.create.node(["Concept1",line.node1],{name:line.node1}) yield node
return node创建概念2节点
LOAD CSV WITH HEADERS FROM "file:///node2.csv" AS line
call apoc.create.node(["Concept2",line.node2],{name:line.node2}) yield node
return node创建关联
LOAD CSV WITH HEADERS FROM "file:///tup.csv" AS line
match (c1:Concept1{name:line.node1}),(c2:Concept2{name:line.node2})
call apoc.create.relationship(c1,line.link,line{.type},c2) yield rel
return rel清除重复节点和关系
MATCH (n:Tag)
WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count
WHERE count > 1
CALL apoc.refactor.mergeNodes(nodelist) YIELD node
RETURN node
MATCH (n:Concept2)
WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count
WHERE count > 1
CALL apoc.refactor.mergeNodes(nodelist) YIELD node
RETURN node
MATCH (a:Concept1)-[r]-(b:Concept2)
WITH a, b, collect(r) as rels
CALL apoc.refactor.mergeRelationships(rels,{properties:"combine"})
YIELD rel
RETURN count(rel)路径查询命令
# 两节点之间的所有路径
MATCH p=(a)-[*]->(b)
RETURN p
# a->b 直接连接
MATCH p=(a)-[]->(b)
RETURN p
MATCH p=(:Concept1{name:"细胞"})-[]->(:Concept2{name:"蛋白质"})
RETURN p
# a-...>b a、b之间有三个关系及两个节点
# 等价于 (a) - () - () -> (b)
MATCH p=(a)-[*3]->(b)
RETURN p
# 路径包含2个以上关系
MATCH p=(a)-[*2..]->(b)
RETURN p
# 路径包含6个以内关系
MATCH p=(a)-[*..6]->(b)
RETURN p
# 路径包含3~5个关系
MATCH p=(a)-[*3..5]->(b)
RETURN p通过三元组csv数据表创建概念网络
这个工作用cmap或者node4j都可以做,cmap适合简单的制图,node4j更适合在服务器端构建知识图谱。下面介绍一下如何通过node4j和一个数据表来生成图库。
部分csv数据表结构如下
| hc | link | tc | role |
|---|---|---|---|
| 细胞 | 包含 | 细胞膜 | |
| 细胞 | 包含 | 细胞质 | |
| 细胞 | 多包含 | 细胞核 | |
| 细胞 | 包含 | 水 | 三分之二 |
其中hc表示head Concept,tc表示tail concept, link是连续词,role是补充说明。
添加节点
LOAD CSV WITH HEADERS FROM "file:///relation.csv" AS line
call apoc.create.node(["Concept",line.hc],{name:line.hc}) yield node
return node
LOAD CSV WITH HEADERS FROM "file:///relation.csv" AS line
call apoc.create.node(["Concept",line.tc],{name:line.tc}) yield node
return node去除重复节点
MATCH (n:Concept)
WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count
WHERE count > 1
CALL apoc.refactor.mergeNodes(nodelist) YIELD node
RETURN node添加链接
LOAD CSV WITH HEADERS FROM "file:///relation.csv" AS line
match (c1:Concept{name:line.hc}),(c2:Concept{name:line.tc})
call apoc.create.relationship(c1,line.link,line{.role},c2) yield rel
return rel查看效果
MATCH p=()-->() RETURN p LIMIT 100
MATCH p=(:Concept{name:"细胞"})-[]->(:Concept{name:"蛋白质"})
RETURN p
MATCH p=(:Concept{name:"细胞"})-[*]->(:Concept{name:"蛋白质"})
RETURN p显示结果如下: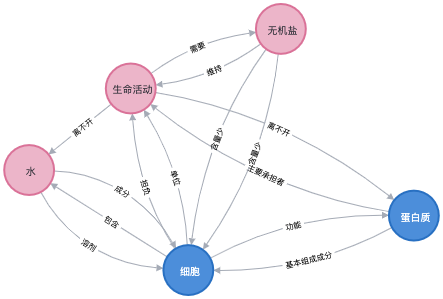
修改和完善图谱
增加节点
CREATE (n:Person {name:'John'}) RETURN n
CREATE (n:Concept {name:'细胞呼吸'}) RETURN n增加链接
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS]->(b)
MATCH (a:Concept {name:'光合作用'}),
(b:Concept {name:'光反应'})
MERGE (a)-[:包含]->(b)
MATCH (a:Concept {name:'光合作用'}),
(b:Concept {name:'暗反应'})
MERGE (a)-[:包含]->(b)
MATCH p=(:Concept{name:"光合作用"})-[*..3]->()
RETURN p LIMIT 100数据库操作
备份数据库
如果你对数据库进行了修改,想保留一个备份以备今后使用,那么可以使用neo4j-admin dump命令。
首先先停止服务,然后在shell环境下,运行:
bin/neo4j-admin dump --database=neo4j --to=/dumps/neo4j/neo4j-<timestamp>.dump具体可以参考官方文档。
加载数据库
你还可以使用neo4j-admin load命令加载一个数据库。如果是替换一个已有数据库,你需要先将其停止运行。
bin/neo4j-admin load --from=/dumps/neo4j/neo4j-<timestamp>.dump --database=neo4j --force复制数据库
使用neo4j-admin copy复制或者选择性复制
STOP DATABASE neo4j
bin/neo4j-admin copy --from-database=neo4j --to-database=copy
ls -al ../data/databases
CREATE DATABASE copy
SHOW DATABASES还可以筛选数据,下面的命令就是删除cat,dog标签的节点
bin/neo4j-admin copy --from-database=neo4j --to-database=copy --delete-nodes-with-labels="Cat,Dog"参考官方文档。

